항해99/TIL
6일차-6/12 토 -항해99
반응형
- 알고리즘 3, 4 주차 강의
- 3주차 내용
- 버블 정렬 : 인접한 두 원소를 대소 비교후 서로의 위치를 바꿔줌
- 선택 정렬 : 가장 작은 값을 찾아서 앞으로 보낸다. 그 다음 위치에서 반복
- 합병 정렬 : 두 문제를 조건에 맞게 정렬하면서 합쳐준다.분할 정복(divide and conquer) 방법
아래 분할 정복(divide and conquer 를 하기 위해 필요)- 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결
- 리스트의 길이가 1이 될때까지 반으로 잘게 나눈다.-> 분할(Divide)
- ㄴ> 이때, 길이가 1일 때 탈출코드를 꼭 작성 해야합니다!
- 다 나누어 졌다면, 데이터를 합치는데(Merge), 정렬하면서 합친다.
— 재귀 호출로 합쳐주게 됩니다.
def merge_sort(array):
if len(array) <= 1:
return array
mid = (0 + len(array)) // 2
left_array = merge_sort(array[:mid]) # 왼쪽 부분을 정렬하고
right_array = merge_sort(array[mid:]) # 오른쪽 부분을 정렬한 다음에
merge(left_array, right_array) # 합치면서 정렬하면 됩니다!- 정렬이 이해가 안된다면 아래 링크들을 참고
[알고리즘] 버블 정렬(bubble sort)이란
[알고리즘] 삽입 정렬(insertion sort)이란
[알고리즘] 합병 정렬(merge sort)이란
- 스택 : 스택은 위의 사진처럼 같은 구조와 크기의 자료를 정해진 방향으로만 쌓을수 있고, top(head)으로 정한 곳을 통해서만 접근할 수 있다.

스택 이라는 자료 구조에서 제공하는 기능!
**push(data)** : 맨 앞에 데이터 넣기
**pop()** : 맨 앞의 데이터 뽑기
**peek()** : 맨 앞의 데이터 보기
**isEmpty()**: 스택이 비었는지 안 비었는지 여부 반환해주기- 큐 : 정해진 한 곳(top)을 통해서 삽입, 삭제가 이루어지는 스택과는 달리 큐는 한쪽 끝에서 삽입 작업이, 다른 쪽 끝에서 삭제 작업이 양쪽으로 이루어진다.
스택과 다르게 큐는 끝과 시작의 노드를 전부 가지고 있어야 하므로,
self.head 와 self.tail 을 가지고 시작합니다!```
큐라는 자료 구조에서 제공하는 기능!
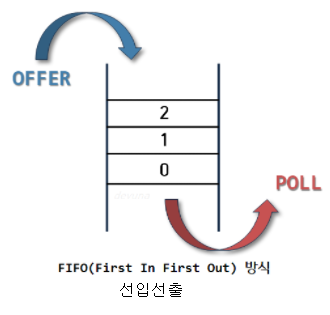
- enqueue(data)* : 맨 뒤에 데이터 추가하기
- dequeue()* : 맨 앞의 데이터 뽑기
- peek()* : 맨 앞의 데이터 보기
- isEmpty()*: 큐가 비었는지 안 비었는지 여부 반환해주기
- 해시 : Hash Table: 키(Key)에 데이터(Value)를 저장하는 데이터 구조
- `단, 파이썬에서는 해쉬를 별도 구현할 이유가 없음 - 딕셔너리 타입을 사용하면 됨...
. 파이썬 딕셔너리 알면 무슨 내용인지 감이온다 - 해쉬 테이블 코드에 Chaining 기법으로 충돌해결 코드
hash_table = list([0 for i in range(8)])
def get_key(data):
return hash(data)
def hash_function(key):
return key % 8
def save_data(data, value):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] == index_key:
hash_table[hash_address][index][1] = value
return
hash_table[hash_address].append([index_key, value])
else:
hash_table[hash_address] = [[index_key, value]]
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] == index_key:
return hash_table[hash_address][index][1]
return None
else:
return Nonesave_data('Dd', '1201023010')
save_data('Data', '3301023010')
read_data('Dd') #'1201023010'
hash_table
[0,
0,
[[1341610532875195530, '1201023010'], [-9031202661634252870, '3301023010']],
0,
0,
0,
0,
0]- 4주차 내용
- 힙 : 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)
부모 노드 인덱스 번호 = 자식 노드 인덱스 번호 // 2 왼쪽 자식 노드 인덱스 번호 = 부모 노드 인덱스 번호 * 2 오른쪽 자식 노드 인덱스 번호 = 부모 노드 인덱스 번호 * 2 + 1
- DFS 와 BFS✔DFS : 깊이 우선 탐색 deepdown 방식으로 한줄기씩 탐색하는 방식
- → 푸는 법 : 스택을 이용하거나 or 재귀함수를 이용하는 법. 보편적으로 재귀를 사용함

- DFS 재귀풀이✔BFS : 너비 우선 탐색 Breadth-First Search 방식으로 한단계, 한층씩 탐색하는 방식
- → 푸는 법 : 큐(queue)를 사용해서 해결✔BFS : 너비 우선 탐색 Breadth-First Search 방식으로 한단계, 한층씩 탐색하는 방식
# DFS 재귀 풀이
# 인접리스트는 아래와 같다.
graph = {
1: [2, 5, 9],
2: [1, 3],
3: [2, 4],
4: [3],
5: [1, 6, 8],
6: [5, 7],
7: [6],
8: [5],
9: [1, 10],
10: [9]
}
visited = []
# 1. 시작노드 (루트노드) 인 1부터 탐색합니다.
# 2. 현재 방문한 노드를 visited_array 에 추가합니다.
# 3. 현재 방문한 노드와 인접한 노드 중 방문하지 않은 노드에 방문합니다.
def dfs_recursion(adjacent_graph, cur_node, visited_array):
# 구현해보세요!
visited_array.append(cur_node)
for adjacent_node in adjacent_graph:
if adjacent_node not in visited_array:
dfs_recursion(adjacent_graph, adjacent_node, visited_array)
return
dfs_recursion(graph, 1, visited) # 1 이 시작노드입니다!
print(visited) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 이 출력되어야 합니다!- BFS 큐(queue)풀이
# DFS 재귀 풀이
# 인접리스트는 아래와 같다.
graph = {
1: [2, 3, 4],
2: [1, 5],
3: [1, 6, 7],
4: [1, 8],
5: [2, 9],
6: [3, 10],
7: [3],
8: [4],
9: [5],
10: [6]
}
# 1. 시작 노드를 큐에 넣습니다
# 2. 현재 큐의 노드를 빼서 visited 에 추가합니다.
# 3. 현재 방문한 노드와 인접한 노드 중 방문하지 않은 노드를 큐에 추가한다
def bfs_queue(adj_graph, start_node):
# 구현해보세요!
queue = [start_node]
visited = []
while queue:
current_node = queue.pop(0)
visited.append(current_node)
for adjacent_node in adj_graph[current_node]:
if adjacent_node not in visited:
queue.append(adjacent_node)
return visited
print(bfs_queue(graph, 1)) # 1 이 시작노드입니다!
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 이 출력되어야 합니다!- Dynamic Programming : 여러 개의 하위 문제 결과를 이용해 상위문제를 해결하는 알고리즘
- 피보나치 수열 → 재귀 + memoization
input = 10
# memo 라는 변수에 Fibo(1)과 Fibo(2) 값을 저장해놨습니다!
memo = {
1: 1,
2: 1,
33: 33
}
# 1. 만약 메모에 값이 있으면 리턴하고
# 2. 없으면 수식을 진행해서 메모에 기록한다.
def fibo_dynamic_programming(n, fibo_memo):
# 구현해보세요!
if n in memo.keys():
return memo[n]
nth_fibo = fibo_dynamic_programming(n - 1, fibo_memo) + fibo_dynamic_programming(n - 2, fibo_memo)
fibo_memo[n] = nth_fibo
return nth_fibo
print(fibo_dynamic_programming(input, memo)) # 55
반응형
'항해99 > TIL' 카테고리의 다른 글
| 8일차-6/14 월 -항해99 (0) | 2021.06.16 |
|---|---|
| 7일차-6/13_항해99_1주차 WIL(회고록) (0) | 2021.06.16 |
| 5일차-6/11 금 -항해99 (0) | 2021.06.14 |
| 4일차-6/10 목 -항해99 (0) | 2021.06.13 |
| 3일차-6/9 수 -항해99 (0) | 2021.06.13 |
댓글