[Selenium+bs4] 네이버 카페 검색창, iframe 크롤링 방법, 네이버 로그인 방법
이 글은 네이버 카페내의 결과에서 게시글 제목을 리스트로 출력하고,
게시글을 순서대로 클릭해서 들어갔다가 나가는 코드 설명입니다.
# 1. iframe이란?
네이버 카페 내에서 카페내 검색 결과를 크롤링하는 방법
일단 iframe 이란 것을 알아야한다.
아이프레임은 HTML Inline Frame 요소이며
inline frame의 약자이다.
" 효과적으로 다른 HTML 페이지를 현재 페이지에 포함시키는 중첩된 브라우저로
iframe 요소를 이용하면 해당 웹 페이지 안에 어떠한 제한 없이 다른 페이지를 불러와서 삽입 할 수 있다. "
라는 어려운 말이지만 눈으로 보면 편하다 아래와 같은 것이 iframe이다

그래서 일반적인 크롤링 방식으로 검색결과를 가져오려고 하면 class 이름이라던지 id를 찾지 못해 에러가 난다.
따라서 iframe 을 Selenium으로 창을 선택해주고 그안의 결과를 가져오는 식으로 진행해야 한다.
아래 코드를 참고하여 iframe의 결과를 가져오는데 도움이 되길 바랍니다.
코드 설명은 그 아래 작성함
# 2. 전체 코드
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
import pandas as pd
driver = webdriver.Chrome("./chromedriver")
driver.get("https://cafe.naver.com/kig")
driver.implicitly_wait(3)
driver.find_element_by_name('query').send_keys('보라매역')
driver.find_element_by_name("query").send_keys(Keys.ENTER)
time.sleep(2)
driver.switch_to.frame("cafe_main")
for i in range(1, 3):
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
titles = soup.select("#main-area > div:nth-child(7) > table > tbody > tr")
print('----' + str(i) + ' 번째 페이지 -----')
list3 = []
for title in titles:
list = title.select_one(' td.td_article > div.board-list > div > a').text
list2 = ''.join(list.split())
list3.append(list2)
list4_sr = pd.Series(list3)
print(list4_sr)
# for a in range(1, 3):
# driver.find_element_by_xpath(f'//*[@id="main-area"]/div[5]/table/tbody/tr[{a}]/td[1]/div[2]/div/a').click()
# time.sleep(3)
# driver.back()
# time.sleep(2)
# driver.switch_to.frame("cafe_main")
if i<2:
driver.find_element_by_xpath(f'//*[@id="main-area"]/div[7]/a[{i}+1]').click()
# 3. 코드 설명
## part 1.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
import pandas as pd먼저 selenium , bs4 , time , pandas를 import 하자
time 은 페이지를 넘어갈 때 약간의 딜레이를 줘 오류를 방지한다.
pandas는 리스트 결과를 출력하기 위함
driver = webdriver.Chrome("./chromedriver") # 크롬 브라우저를 driver로 지정
driver.get("https://cafe.naver.com/kig") # 원하는 카페 주소를 입력
driver.implicitly_wait(3) # 대기시간 3초
driver.find_element_by_name('query').send_keys('보라매역') # 원하는 검색어를 검색창에 입력
driver.find_element_by_name("query").send_keys(Keys.ENTER) # 그리고 엔터를 입력해 검색
time.sleep(2) # 2초 대기
driver.switch_to.frame("cafe_main")이 부분이 핵심이다. 결과가 나온 게시물들은 iframe 안에 있기 때문에
driver창의 frame 을 iframe의 태그인 cafe_main 으로 바꿔줘야
bs4로 원하는 내용을 가져올 수 있다.
frame 변경을 하지 않으면 iframe 밖의 개체밖에 가져오지 못하고
반대로 iframe 으로 변경하면 밖의 개체를 가져올 수 없다.
## part.2
for i in range(1, 3):
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
titles = soup.select("#main-area > div:nth-child(7) > table > tbody > tr")
print('----' + str(i) + ' 번째 페이지 -----')
list3 = []
for title in titles:
list = title.select_one(' td.td_article > div.board-list > div > a').text
list2 = ''.join(list.split())
list3.append(list2)
list4_sr = pd.Series(list3)
print(list4_sr)
# for a in range(1, 3):
# driver.find_element_by_xpath(f'//*[@id="main-area"]/div[5]/table/tbody/tr[{a}]/td[1]/div[2]/div/a').click()
# time.sleep(3)
# driver.back()
# time.sleep(2)
# driver.switch_to.frame("cafe_main")
## 게시글을 클릭하고 뒤로 돌아온 경우에는 switch로 다시 iframe을 선택해 주어야 한다.
if i<2:
driver.find_element_by_xpath(f'//*[@id="main-area"]/div[7]/a[{i}+1]').click()
# 결과 다음 페이지로 가는 구문, 다음페이지로 간 경우 iframe 은 선택 되어 있으므로
# 스위치를 안써줘도 된다.
for 구문은 검색 결과 게시글 제목을 리스트로 저장, 출력하는 코드이다.
주석 처리한 내용은 게시글을 클릭해서 들어가고 다시 뒤로 오는 구문이다.
게시글 클릭 구문에 switch로 iframe 을 다시 선택해주어야한다.
그래야 뒤로가기로 결과창으로 돌아와서 다시 iframe 을 선택 해주기 때문이다.
꿀팁으로 switch 구문에서 에러가 잘 발생하는데
이유는 iframe이 이미 선택되어 있는 상태에서
switch로 iframe을 또 선택하면 에러가 발생한다.
한번에 코드를 잘 짜면 좋지만 많은 for 반복문으로 헷갈릴 때,
혹은 러프하게 코딩을 할 땐
아래와같이 오류가 있을 땐 실행을 안하고
선택을 해야하는 경우엔 실행이 되게끔
try / except 구문을 이용하자
try:
driver.switch_to.frame("cafe_main")
except:
pass혹은 함수형태로 앞쪽에 만들어서 호출해서 사용하면 된다.
def iframe():
try:
driver.switch_to.frame("cafe_main")
except:
pass
# 4. 결과
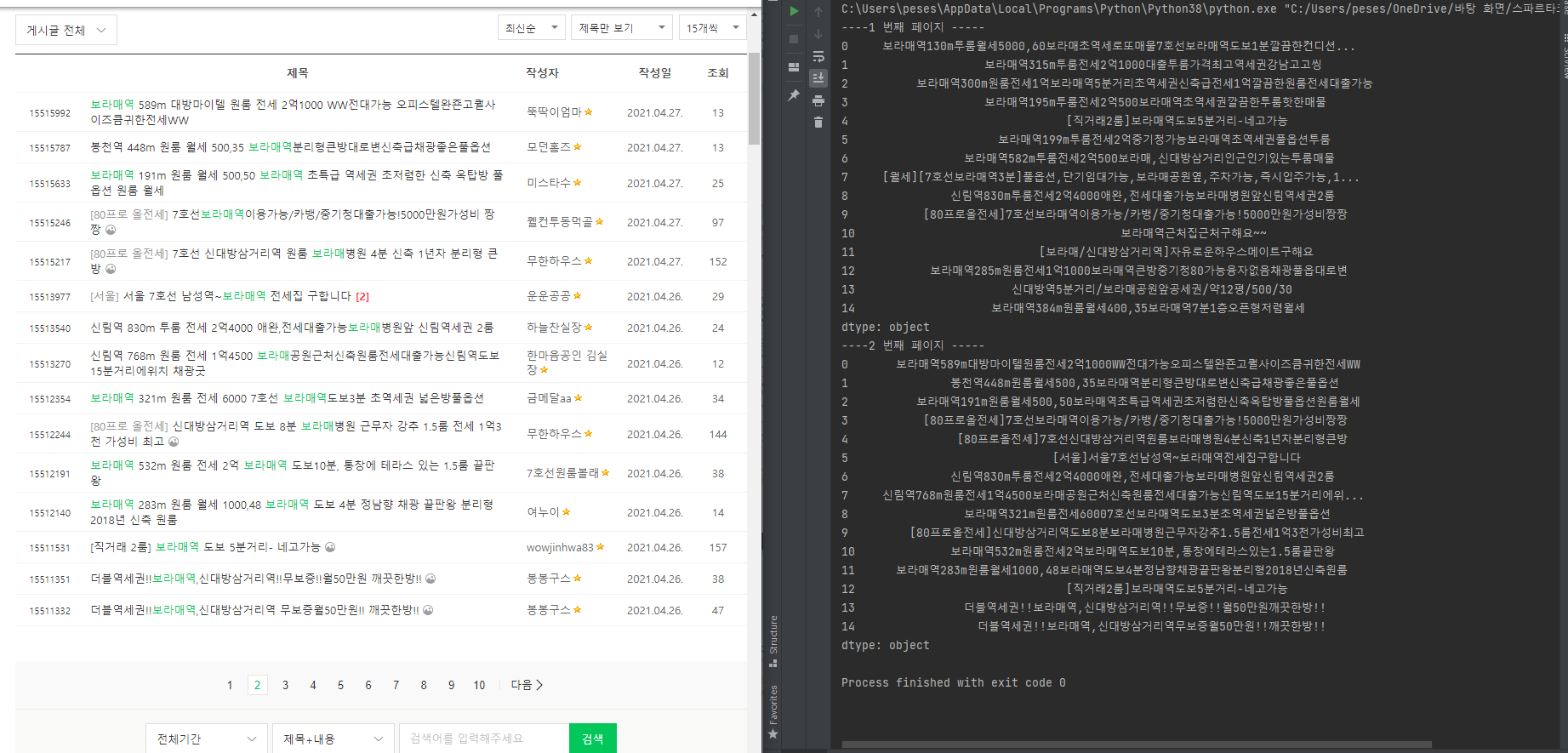
+ 내용 추가
첫 for 문의 beatifulsoup 관련 사용법
for i in range(1, 3):
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
titles = soup.select("#main-area > div:nth-child(7) > table > tbody > tr")
ㅇ여기서 soup.select ("게시물제목의 copyselect주소")
주소는 copyselector 로 가져옵니다.

첫 번째와 두 번째 게시물의 copyselector 주소를 가져와 보면
# 리스트 타이틀 참조 -copyselector
첫번째 : # main-area > div:nth-child(7) > table > tbody > tr:nth-child(1) > td.td_article > div.board-list > div > a
두번째 : # main-area > div:nth-child(7) > table > tbody > tr:nth-child(2) > td.td_article > div.board-list > div > a
위와 같습니다. tr:nth-child(1) / (2) 이 부분이 다른 걸 봐서 게시글이 다음으로 갈 수록
숫자가 커진다는 것을 알 수 있습니다
따라서 앞쪽의 주소만 따와서
titles = soup.select('#main-area > div:nth-child(7) > table > tbody > tr') 으로 작성합니다.
그리고나서 이제 남은 부분인 'td.td_article > div.board-list > div > a' 이 부분은
그 아래 for문에서 쓰입니다.
for title in titles:
list = title.select_one(' td.td_article > div.board-list > div > a').text
list2 = ''.join(list.split())
list3.append(list2)for문을 공부하셨으면 아래 구문의 title에 titles (리스트)의 항목이 차례대로 들어가면서 반복 되는 것을 알 수 있으실 겁니다요
1번째 실행에 # main-area > div:nth-child(7) > table > tbody > tr:nth-child(1)
2번째 실행에 # main-area > div:nth-child(7) > table > tbody > tr:nth-child(2)
...
그럼이제 그 항목 중에 글자만 따오기 위해서
select_one('항목').text 를 작성 해줄 것 입니다.
항목은 위에서 짤라 쓴 주소의 뒷 부분이 됩니다.
# main-area > div:nth-child(7) > table > tbody > tr:nth-child(1) > td.td_article > div.board-list > div > a
그래서 list = title.select_one(' td.td_article > div.board-list > div > a').text 이 됩니다요.
하지만 위의 copyselect 주소는 인터넷 사이트마다 다릅니다.
다른 네이버 카페에서는 copyselector 주소가 다르므로
연습하고자 하는 카페의 주소를 가져와야 쓰실 수 있으십니다요!!!
참고로 아래의 xpath도 마찬가지 입니다!!
if i<2:
driver.find_element_by_xpath(f'//*[@id="main-area"]/div[7]/a[{i}+1]').click()driver.find_element_by_xpath(f'//*[@id="main-area"]/div[7]/a[{i}+1]').click()
//*[@id="main-area"]/div[7]/a[{i}+1] 이 주소는 아래와 같이 가져옵니다.
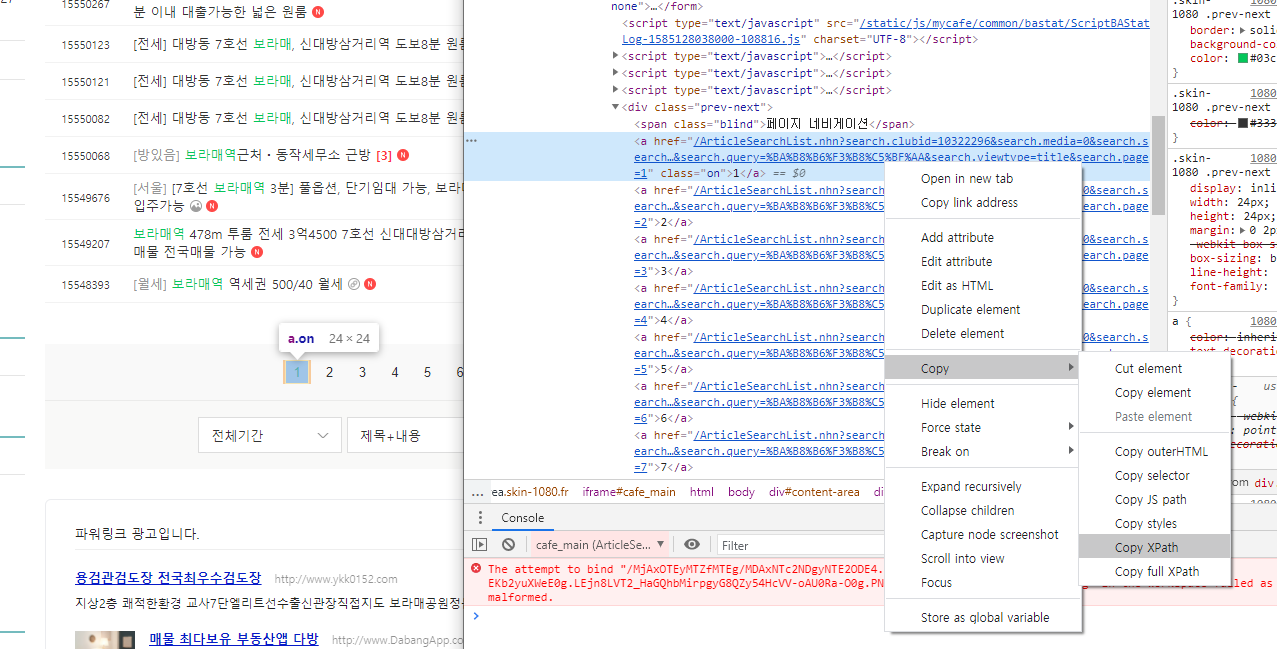
1페이지 , 2페이지의 다름을 알기 위해 두개를 가져와보니
.# 페이지 번호 XPATH 참조
# //*[@id="main-area"]/div[7]/a[1]
# //*[@id="main-area"]/div[7]/a[2]
# //*[@id="main-area"]/div[7]/a[3]
맨 뒷부분의 숫자만 다르군요!!
제가 반복하고자 하는 범위는 맨 윗쪽 for문 에 적었습니다.
for i in range(1, 3): # 두 번째 페이지까지만 반복합니다..
driver.find_element_by_xpath(f'//*[@id="main-area"]/div[7]/a[{i}+1]').click()
f ' ' 로 변수 {i} 를 받아왔습니다
(f'' 스트링은 내용 안쪽에 변수를 {변수} 형태로 작성 가능하게합니다.)
이제 i값에 따라 페이지 번호가 변하겠네요!
i 가 1 이면 첫번째 페이지이므로 이미 첫 페이지니까 +1을 해줘서
두 번째 페이지로 이동합니다.
i 가 2 이면 세번 째 페이지로 가지는데 그러고 싶지 않아서
if i < 2 로 제한을 주었습니다.
설명이 충분했으면 좋겠어요,,
저도 이제 공부 시작한 코린이라ㅎㅎㅎ
우리 힘내요👍👍
++내용추가 : 댓글 작성 방법
게시글에 들어가서 댓글을 작성하는 방법입니다.
1. 먼저 댓글창의 xpath를 가져옵니다.
2. 같은 방법으로 등록 버튼의 xpath도 가져옵니다.


ㅇ댓글 텍스트 작성공간
//*[@id="app"]/div/div/div[2]/div[2]/div[5]/div[2]/div[1]/textarea
ㅇ댓글 등록 버튼
//*[@id="app"]/div/div/div[2]/div[2]/div[5]/div[2]/div[2]/div[2]/a
3. 이제 다 됐습니다. 작성공간에 글자만 써주고나서 바로 등록을 누르게 코드를 입력해주면 끝!
*게시글 들어가고 로딩되는 약간의 시간(0.5)을 주었습니다
time.sleep(0.5)
driver.find_element_by_xpath('//*[@id="app"]/div/div/div[2]/div[2]/div[5]/div[2]/div[1]/textarea').send_keys("여기에 댓글")
driver.find_element_by_xpath('//*[@id="app"]/div/div/div[2]/div[2]/div[5]/div[2]/div[2]/div[2]/a').click()
🚩댓글을 못달고 에러가 뜨는 이유
네이버 카페는 로그인이 되고 해당 게시물에 들어갔을 때 댓글창이 보여야 댓글의 xpath를 찾을 수 있다.
해결하려면 로그인을 해야하는데 문제점이 2가지있다.
- 로그인 할 계정에 2차 인증기능이 켜져있으면 안된다. -> 네이버 계정 보안 설정에서 2차인증을 끄자
- 인터넷에 많이 올라와 있는 네이버 로그인 하는 법에는 아래와 같은 문제가 있다
driver.get("https://nid.naver.com/nidlogin.login?url=http://section.cafe.naver.com")
time.sleep(1)
user_id = driver.find_element_by_id("id")
user_id.send_keys("아이디입력")
password = driver.find_element_by_id("pw")
password.send_keys("비밀번호입력")
password.submit()
time.sleep(1)
driver.find_element_by_id("new.dontsave").click()위와 같은 코드는 많이 볼 수 있는데 정작 실행하면 자동입력 방지문자를 입력하라고 한다,,,,,ㅠㅠ
그래서 해결하는 방법을 찾았다. 좀 귀찮은 방법이지만 작동은 되니까,,,,
다른 아이디어 있으면 알려주세요
네이버 로그인 문제점 해결
네이버 로그인 방법엔 일반 아이디로그인과 QR로그인, 그리고 일회용 번호 로그인 방법이 있다.
그 중 일회용 로그인을 이용해서 접속을 하면 된다.

- 해결법
휴대폰으로 네이버 앱을 깔고 로그인 할 아이디의 2차 인증은 미리 해제해주세요.
로그인을 한 뒤 다음과 같이 일회용 로그인 번호 받기 창으로 이동해준다.




요런 상태까지 했으면 로그인하는 코드를 맨 위에 작성하자
다음과 같이 코드를 입력한다.
driver = webdriver.Chrome("./chromedriver")
"""
네이버 일회용 로그인
"""
driver.get("https://nid.naver.com/nidlogin.login?url=http://section.cafe.naver.com")
time.sleep(1)
driver.find_element_by_id("log.otn").click()
user_id = driver.find_element_by_id("disposable")
user_id.send_keys("띄어쓰기 없이 일회용 번호를 입력해주세요")
driver.find_element_by_id("otnlog.login").click()
time.sleep(2)폰의 일회용 번호시간이 넉넉할 때
잽싸게 위의 번호입력하는 곳에 입력하고
실행하면 로그인이 성공한다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
전체코드는 다음과 같다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome("./chromedriver")
"""
네이버 일회용 로그인
"""
driver.get("https://nid.naver.com/nidlogin.login?url=http://section.cafe.naver.com")
time.sleep(1)
driver.find_element_by_id("log.otn").click()
user_id = driver.find_element_by_id("disposable")
user_id.send_keys("15597038")
driver.find_element_by_id("otnlog.login").click()
time.sleep(2)
exit(0)
driver.get("https://cafe.naver.com/joonggonara")
driver.implicitly_wait(3)
driver.find_element_by_name('query').send_keys('과자')
driver.find_element_by_name("query").send_keys(Keys.ENTER)
time.sleep(2)
driver.switch_to.frame("cafe_main")
for i in range(1, 3):
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
titles = soup.select("#main-area > div:nth-child(7) > table > tbody > tr")
for a in range(1, 2):
driver.find_element_by_xpath(f'//*[@id="main-area"]/div[5]/table/tbody/tr[{a}]/td[1]/div[2]/div/a').click()
time.sleep(3)
driver.find_element_by_xpath('//*[@id="app"]/div/div/div[2]/div[2]/div[5]/div[2]/div[1]/textarea').send_keys(
"여기에 댓글")
driver.find_element_by_xpath('//*[@id="app"]/div/div/div[2]/div[2]/div[5]/div[2]/div[2]/div[2]/a').click()
time.sleep(0.5)
driver.back()
time.sleep(2)
driver.switch_to.frame("cafe_main")
if i < 2:
driver.find_element_by_xpath(f'//*[@id="main-area"]/div[7]/a[{i}+1]').click()
def iframe():
try:
driver.switch_to.frame("cafe_main")
except:
pass
2021.04.08 - [python/Selenium 셀레니움] - [selenium] 크롤링 selenium 셀레니움 사용법, 명령어 모음
[selenium] 크롤링 selenium 셀레니움 사용법, 명령어 모음
#0. 셀레니움 실행을 위한 chrome 드라이버 다운로드 사용중인 chrome 버전으로 드라이버를 다운로드 한다. 크롬 버전 확인 (주소창에 복붙) chrome://version 크롬 드라이버 다운로드 링크 chromedriver.chromi
gorokke.tistory.com
2021.03.29 - [python/beatifulsoup 뷰티풀스프] - [python]파이썬 크롤링, mongodb, html, flask, bs4 활용
[python]파이썬 크롤링, mongodb, html, flask, bs4 활용
1. API 역할 url 받고 메시지 호출 2. 로딩이 되면 자동 요청 되는 부분 $(document).ready( function() { 함수이름(); }) #1. 서버쪽 (app.py) : robo 3T (mongodb 에 저장 된 내용) 정보를..
gorokke.tistory.com
'python > Selenium 셀레니움' 카테고리의 다른 글
| [selenium] 크롤링 selenium 셀레니움 사용법, 명령어 모음 (4) | 2021.04.08 |
|---|
댓글